Introduction
This simple question came up when I was looking after a neglected server, seeing too many logfiles piling up in it. Such extreme file overflows can go unnoticed until the related application slows down, breaks, the filesystem space or its inodes are exhausted. In the case of log files, the generating application or script is often unaffected and filesystem space is so plenty today that the limits are not reached quickly.
In my example, the directory in question was having 80.000 log files with a history dating back several years. While cleaning up I became interested in looking at the implications, limits and practicality of having huge numbers of files.
The same question about potentially getting large amounts of files comes up when designing an application. The usual standard solution is to put the data into a database, adding complexity from the start.
However, if the number of data files is not expected to be extremely huge and data relations do not require extensive cross-referencing, storing application data in good old flat files can be a excellent choice. The filesystem in itself is already a very performant form of a database.
Those of you who run a News or BBS system probably know the implications by experience. When I was trying to read up more details about filesystems and their theoretical and practical limits, I found a lot of inconsistent, unclear information on the web.
Filesystem Constraints
Basically it comes down to this:
- The number of files per directory depends on the filesystem and its parameters.
- In most filesystems, there is no limiting maximum number of files per directory.
- On Inodes-based Filesystems, the max. number of files depends on avail. inodes, whose allocation is theoretically unlimited but depends on the inode to space ratio that had been set.
Practical Tests
I wanted a quick practical test, so I prepared a test script to run on a few exemplary filesystems that were generated with default parameters. The script generates small dummy files in a infinite loop while checking how the system copes with it. Unfortunately, the quick tests didn't include 'df -i' to see the inodes shrinking, it would have been interesting to see that too.
Test Results
Even on a untuned standard filesystem, I did not hit any limits but simply run out of time, so I decided to stop file generation at 150.000 files.
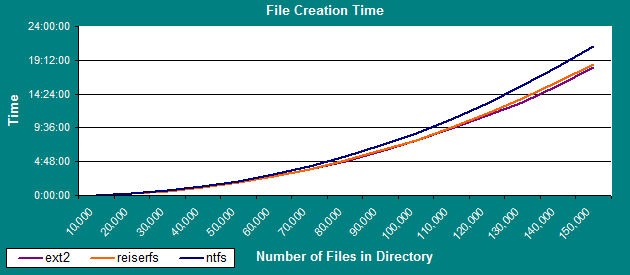
The chart above shows: File generation slowed down quickly and noticeably whith increasing file numbers, I think mostly due to writing the ever-increasing directory file back to disk. While the first 10k files had been created in 2-3 minutes, it took almost 3 hours to create the last 10k files. Above times will improve on systems having much better I/O, but the basic curve is expected to be the same. Now lets see the size of the directory file:
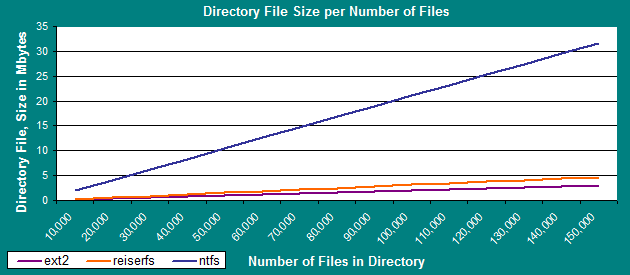
While the ext2 filesystem grew the directory file size to about 3 MB, reiserfs grew the direcory file to about 4 MB, but NTFS blew the directory file up to a whopping 32 MB.
Under ext2 and reiserfs, for normal file operations, there was no perceived impact when working in a directory with 150.000 files while listing, reading, copying or moving files except for shell expansion issues, more about that below.
With NTFS even simple operations became unworkable, a simple 'ls -l | more' commands takes forever (33 seconds) to respond with output.
From here on, the article is not quite finished yet, still work in progress...
Additional Hints to work with large file numbers
Selecting file groups out of the large file pool becomes a problem because most UNIX commands expand wildcard parameters using the shell. For example, ls 1* fails because its expanded to ls 1.txt 11.txt, 12.txt ...
Use 'echo *' to list the content of the current directory, or better, use xargs together with find:
find /archive -type f -name '*' -print | xargs -l64 -i mv -f {} /oldfiles
find . -name 'filename' -exec rm {} \;
Without xargs, find has to fork() and exec() an separate /usr/bin/rm process to remove each individual file, which causes significant system overhead. By using xargs, find only needs to do this once for every X number of files, where X is the number of files that fit on one command line.
Some interesting knowledge extracted from the filesystem documentation:
ext2fs theoretical file per directory limit: 1.3 × 1020 files
In ext2fs, directories are files that are managed as linked lists of variable length entries. Each entry contains the inode number, the entry length, the file name and its length. So, with getting lots of files per directory, the directory file size itself increases, allocating more data blocks if needed.